
【導(dǎo)讀】近日,摩爾線程正式發(fā)布并開源面向GPU底層算子生成的專用代碼大模型MusaCoder。這是業(yè)內(nèi)首個基于國產(chǎn)GPU算力底座完成全鏈路訓(xùn)練與驗證的開源代碼大模型,其完整后訓(xùn)練流程均在基于MTT S5000構(gòu)建的夸娥智算集群上完成。在KernelBench嚴(yán)格評測中,MusaCoder-27B-RL以O(shè)verall Pass@8 93.2%、Avg.@8 88.60%的成績,超越Claude Opus 4.7、GLM-5.1、DeepSeek-V4 Pro、Kimi K2.6等主流SOTA代碼模型,展現(xiàn)出在GPU原生Kernel生成任務(wù)上的領(lǐng)先性能。
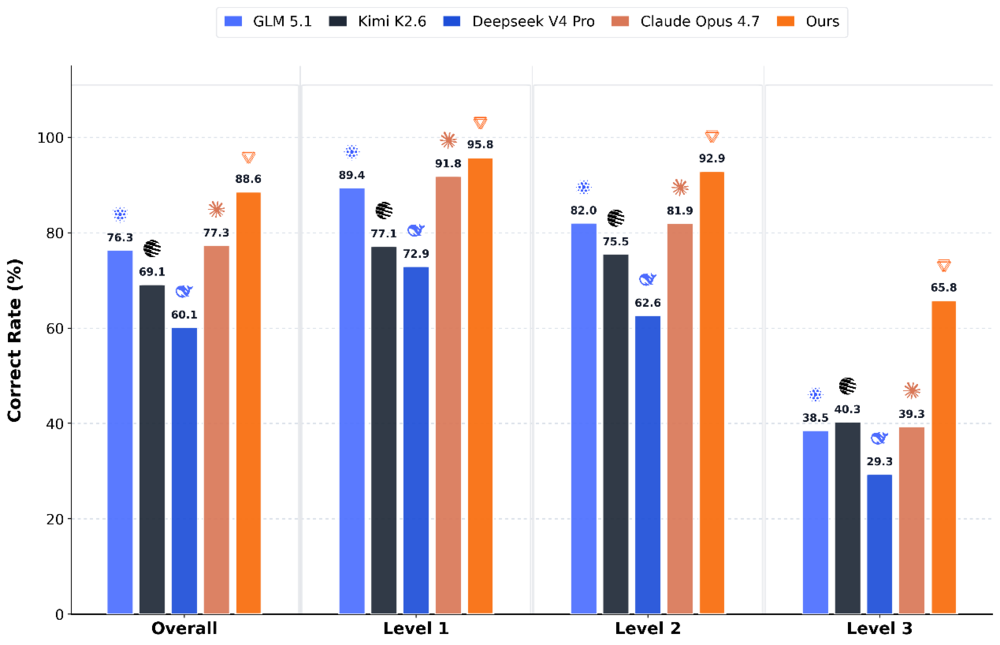
KernelBench準(zhǔn)確率(Avg.@8)對比
MusaCoder模型權(quán)重已開源:https://huggingface.co/MooreThreads/MusaCoder-27B
MusaCoder論文地址:http://arxiv.org/abs/2606.04847
MusaCoder:專為GPU設(shè)計的高性能算子生成模型
MusaCoder是摩爾線程面向GPU底層算子生成任務(wù)設(shè)計的專用代碼大模型,包含9B和27B兩個參數(shù)規(guī)模。該模型重點支持從PyTorch標(biāo)準(zhǔn)算子自動生成高性能CUDA/MUSA原生Kernel代碼,旨在降低開發(fā)者手寫底層GPU算子的門檻,提升GPU高性能計算場景下的代碼生成、驗證和優(yōu)化效率。
傳統(tǒng)代碼大模型雖然具備較強的通用編程能力,但在GPU Kernel生成任務(wù)中仍面臨顯著挑戰(zhàn):一方面,GPU Kernel 對并行計算、線程組織、內(nèi)存訪問、索引映射和硬件執(zhí)行特性要求極高;另一方面,生成代碼不僅要語法正確,還必須能夠通過編譯、數(shù)值正確性驗證、反作弊檢測,并在真實執(zhí)行中獲得性能收益。
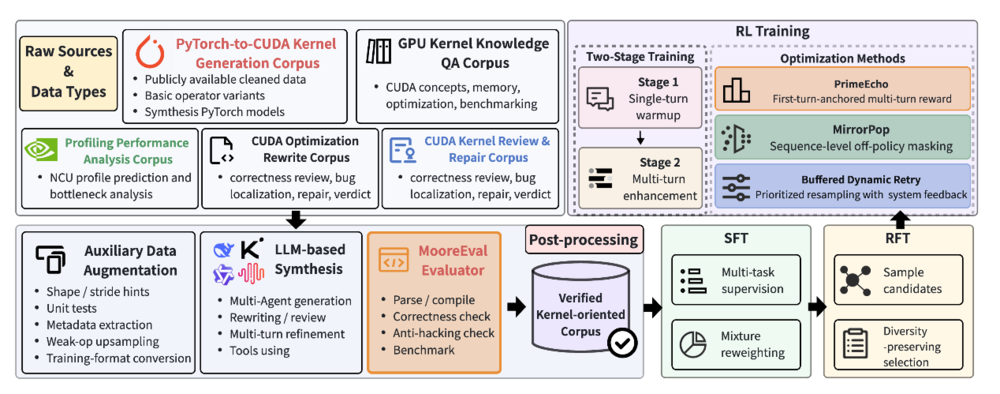
MusaCoder訓(xùn)練總流程
針對上述難點,MusaCoder構(gòu)建了一套面向GPU原生算子(CUDA/MUSA)生成的大模型全棧后訓(xùn)練方法論。該流程覆蓋數(shù)據(jù)構(gòu)建、執(zhí)行驗證、強化學(xué)習(xí)優(yōu)化等關(guān)鍵環(huán)節(jié),使模型能夠從基礎(chǔ)代碼能力逐步進(jìn)化為具備底層算子生成與修復(fù)能力的專用模型。
在數(shù)據(jù)構(gòu)建階段,MusaCoder 通過結(jié)構(gòu)化推理過程和顯式 Shape 信息注入,增強模型對張量形狀、內(nèi)存布局和索引關(guān)系的理解,解決從通用代碼能力遷移到 GPU Kernel 生成任務(wù)時的冷啟動問題。
在評測與訓(xùn)練環(huán)境方面,摩爾線程構(gòu)建了 MooreEval 分布式執(zhí)行驗證系統(tǒng)。MooreEval 能夠?qū)δP蜕傻拇a進(jìn)行自動編譯、執(zhí)行、正確性驗證、性能測試和反作弊檢測,并將結(jié)果轉(zhuǎn)化為穩(wěn)定的訓(xùn)練反饋信號。這使得模型不僅能學(xué)習(xí)“寫出能運行的代碼”,還能夠進(jìn)一步學(xué)習(xí)“寫出正確、合法且更高效的原生 GPU Kernel”。
在強化學(xué)習(xí)階段,MusaCoder針對GPU Kernel生成任務(wù)中的多輪修復(fù)、訓(xùn)練穩(wěn)定性和長尾困難樣本等問題,引入了PrimeEcho、MirrorPop和BDR等機(jī)制,用于提升模型在多輪調(diào)試場景下的修復(fù)能力和訓(xùn)練穩(wěn)定性。通過這些方法,MusaCoder打通了從基礎(chǔ)代碼微調(diào)到執(zhí)行反饋強化學(xué)習(xí)的完整優(yōu)化閉環(huán)。
核心成果:正確率與真實加速能力雙提升
在MooreEval執(zhí)行式驗證協(xié)議下,MusaCoder-27B-RL在KernelBench評測中取得了顯著領(lǐng)先表現(xiàn)。
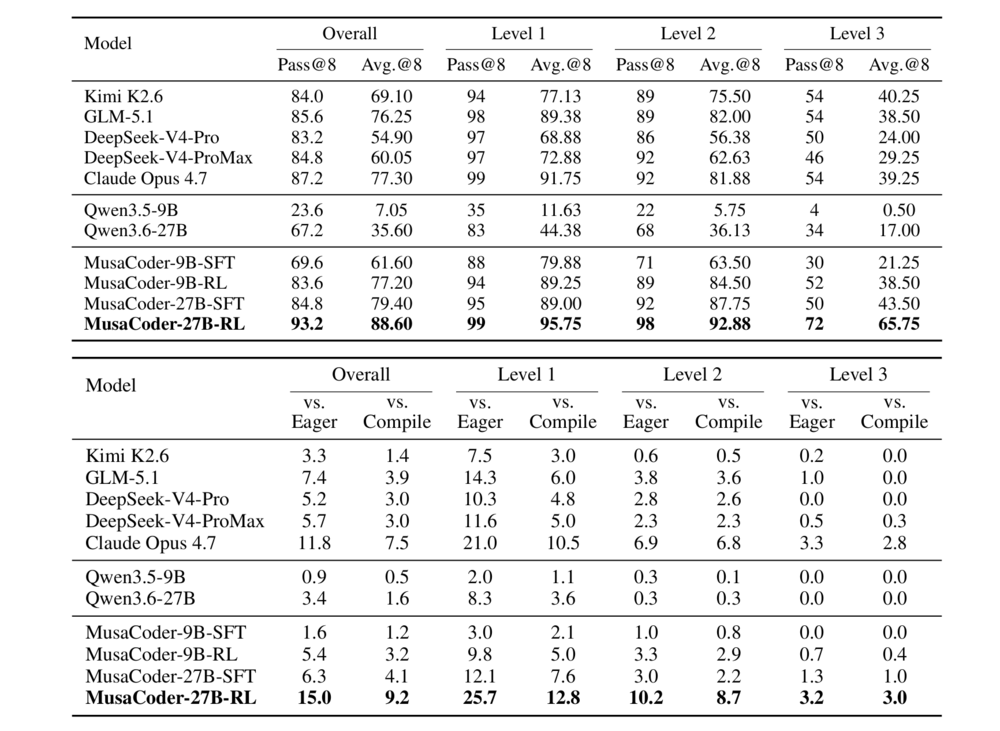
表1:KernelBench評估結(jié)果對比。Pass@8表示8個采樣代碼中至少有一個通過驗證,而Avg.@8則衡量8個樣本的平均正確率。
高準(zhǔn)確率超越SOTA:從正確率來看,MusaCoder-27B-RL的Overall Pass@8達(dá)到93.2%,Avg.@8達(dá)到88.60%,均超過Claude Opus 4.7的87.2%和77.30%。在更具挑戰(zhàn)性的Level 3任務(wù)上,MusaCoder-27B-RL的優(yōu)勢更加明顯。Level 3任務(wù)通常涉及復(fù)雜shape推導(dǎo)、索引映射和多算子組合,對模型的底層代碼理解能力和調(diào)試能力提出了更高要求。在該難度級別上,MusaCoder-27B-RL的Pass@8和Avg.@8分別領(lǐng)先Claude Opus 4.7的18個百分點和26.5個百分點。
真實加速能力突出:在MooreEval標(biāo)準(zhǔn)下,只有同時通過正確性驗證、合法性檢查,并且相比PyTorch baseline獲得有效加速的候選實現(xiàn),才會被計入 Faster Rate。MusaCoder-27B-RL的Overall Faster Rate達(dá)到15.0%(vs. PyTorch Eager)和9.2%(vs. torch.compile),分別高于Claude Opus 4.7的 11.8%和7.5%。
這表明MusaCoder不僅能夠更穩(wěn)定地生成正確的GPU Kernel,也更有能力生成具備實際性能收益的原生算子代碼。
國產(chǎn)GPU完成全流程后訓(xùn)練,驗證夸娥智算集群能力
MusaCoder模型的SFT(監(jiān)督微調(diào))、RFT(拒絕采樣微調(diào))、RL(強化學(xué)習(xí))、異步rollout、在線編譯執(zhí)行驗證及reward計算等全棧訓(xùn)練與驗證流程,均依托摩爾線程旗艦級AI訓(xùn)推一體智算卡MTT S5000所構(gòu)建的夸娥智算集群完成。
這一成果,充分驗證了國產(chǎn)GPU不僅能夠支撐大模型推理和常規(guī)微調(diào)任務(wù),更能夠穩(wěn)定承載代碼大模型后訓(xùn)練全周期算力需求。尤其是在GPU Kernel生成這一類任務(wù)中,訓(xùn)練系統(tǒng)需要頻繁進(jìn)行代碼生成、編譯、執(zhí)行、驗證和反饋計算,對硬件、編譯棧、運行時、調(diào)度系統(tǒng)和評測基礎(chǔ)設(shè)施都提出了更高要求。
MusaCoder的成功實踐,將一次模型訓(xùn)練驗證沉淀為可復(fù)用的工程范式:不僅為AI Coding、AI Infra等基礎(chǔ)設(shè)施的自主可控提供了實踐范例,也展現(xiàn)了摩爾線程在AI軟件棧、訓(xùn)練平臺、評測系統(tǒng)和開源模型生態(tài)方面的完整工程支撐能力。
共建開放生態(tài),推動國產(chǎn)AI創(chuàng)新與應(yīng)用
MusaCoder的正式開源,旨在為MUSA生態(tài)提供面向PyTorch到原生算子生成的基礎(chǔ)模型能力,幫助開發(fā)者更高效地完成GPU Kernel 的生成、驗證、修復(fù)和優(yōu)化,降低底層算子開發(fā)門檻。
同時,MusaCoder也為高校、科研機(jī)構(gòu)和開源社區(qū)提供了一個基于國產(chǎn)全功能GPU的代碼生成研究平臺,推動異構(gòu)計算編程、AI編譯優(yōu)化和自動化Kernel生成等方向的開放研究與技術(shù)交流。
未來,摩爾線程將持續(xù)增強MusaCoder在復(fù)雜任務(wù)上的生成與修復(fù)能力,并進(jìn)一步探索與IDE插件、自動調(diào)試工具、profiling工具等開發(fā)者工具鏈的結(jié)合,逐步形成從PyTorch參考實現(xiàn)到MUSA原生Kernel的自動生成、驗證、修復(fù)和優(yōu)化閉環(huán),持續(xù)推動國產(chǎn)GPU生態(tài)建設(shè)與AI基礎(chǔ)設(shè)施創(chuàng)新。


